





La base del funcionamiento de las computadoras que usamos hoy en día es la Lógica Booleana, que no es más que un sistema que convierte una señal de entrada (input) en una respuesta definida o salida (output) en función a una orden llamada puerta (gate). La expresión física de este operador booleano es la puerta lógica. Por ejemplo, las puertas de este operador booleano pueden ser: YES, AND, OR; los cuales describen el tipo de salida que es generado en función a la señal de entrada.
Para explicar mejor esto, les daré un ejemplo sencillo. Cómo funcionan los motores de búsqueda.
Si ponemos en un buscador la palabra “bacteria” (input), el operador booleano YES (gate), generará una lista de documentos que tienen la palabra “bacteria” (output).
Si ahora ponemos en el buscador las palabras “bacteria” AND “patógena”, se generará una lista de documentos donde estén presentes las dos palabras al mismo tiempo, o sea “bacteria patógena”.
Si ponemos “bacteria” OR “patógena”, se generará una lista de documentos donde aparecerán al menos una de las dos palabras, o bien “bacteria”, o bien “patógena”, o bien “bacteria patógena”.
En una computadora, el output de una primera puerta, puede ser usada como input para una segunda puerta, y a su vez, este nuevo output generado puede ser un input para una tercera puerta, así sucesivamente… formándose unas redes jerárquicas Booleanas, que permiten a un computador resolver operaciones complejas.
Estas puertas lógicas han sido implementadas electrónicamente con el uso de transistores, los cuales son ensamblados en circuitos integrados generando las computadoras basadas en el silicio, reemplazando a las obsoletas válvulas de vacío. La ventaja de los transistores era su velocidad y tamaño, que permitieron el gran desarrollo de la electrónica durante la segunda mitad del siglo XX.

De no ser por los transistores, no tendríamos computadoras que pueden caber en la palma de la mano; sin embargo, la gran demanda de supercomputadoras cada vez más pequeñas, rápidas y portátiles, ha impulsado a los científicos a desarrollar ordenadores cuyas piezas sean hechas a base de átomos o moléculas: los ordenadores cuánticos (basado en el estado de un átomo) y moleculares (basado en las reacciones químicas).
La molécula de ADN, la cual codifica toda la complejidad de la vida en la Tierra, es quizá la forma más poderosa de almacenamiento y procesamiento de datos conocido, y su potencial aplicación en la computación aún no ha sido desarrollada.
Es así que Ki Soo Park y colaboradores del Instituto Coreano del Avance de la Ciencia y Tecnología han desarrollado una puerta lógica basada en el ADN. Park et al. usó la replicación de una secuencia específica de ADN como el output —el cual lo visualizó mediante una electroforesis— y distintos tipos de primers como puertas, las cuales amplificaban o no la secuencia de ADN dependiendo de la presencia de unos determinados iones que actúan como input. Ahora les explicaré de manera más sencilla y detallada.
La replicación del ADN es un proceso por el cual la enzima ADN polimerasa genera una copia similar de un pedazo de ADN que sirve como molde y que se encuentra entre dos pequeñas secuencias iniciadoras llamadas cebadores o “primers”. Por cada ciclo de replicación se generará el doble de la cantidad de las secuencias iniciales, o sea, habrá una amplificación de una secuencia específica de ADN. A esto se le conoce como PCR (reacción en cadena de la polimerasa).
Los primers reconocen secuencias específicas complementarias de ADN para poder unirse a él e iniciar el proceso de replicación. Así que Park et al. diseñó primers con substituciones en uno o dos nucleótidos para ser usados como puertas. Estos nucleótidos modificados generaban un mal apareamiento con el ADN molde complementario, o sea un “mismatch”.
Park et al. usaron dos tipos de substituciones: una Adenina (A) que se complementa con una Timina (T), fue cambiada por una T, generando un mismatch T – T, y una Guanina (G) que se complementa con una Citosina (C) fue cambiada por una C, generando un mismatch C – C. Cuando se presenta un mismatch, la replicación del ADN no procede porque este mal apareamiento genera algo así como un “rompemuelle” o joroba que restringe el paso de la ADN polimerasa.
Sin embargo, estos mismatch pueden ser pasados por alto de tres maneras: 1) usando una enzima que puede replicar el ADN aún en presencia de un mismatch, 2) añadiendo iones de mercurio (Hg+2) a la solución que permite curar el mismatch T – T, formando T – Hg+2 – T y 3) añadiendo iones de plata (Ag+) a la solución para curar el mismatch C – C, formando C – Al+ – C. La afinidad de estos iones por los nucleótidos es sumamente alta y no es afectada por la presencia de otros iones en el medio, permitiendo que la enzima supere el mismatch.
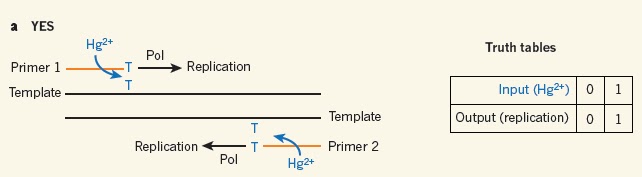
Para la primera puerta YES, la más simple de todas, basta con la presencia del primer con el mismatch T – T (gate) y el Hg+2 (input) para que se de la replicación de la secuencia específica de ADN (output). Si no está presente el ión, no se dará la replicación y el output será negativo.
Para la puerta AND, se requiere de dos primers, uno que replique el ADN en sentido delantero con el mismatch T – T, y otro que replique el ADN en sentido reversa con el mismatch C – C, de esta manera, sólo cuando estén presente los iones Hg+2 y Ag+ (input), se replicará la secuencia específica (output). Si no hay iones o uno de los iones está presente y el otro no, no habrá amplificación de la secuencia específica, o sea el output será negativo.

Para la puerta OR, se requiere también de dos primers, pero los dos deben unirse a las dos hebras de ADN, para que en presencia de uno o de los dos iones, se amplifique la región específica de ADN que tendrá el mismo tamaño en los dos casos.

Y para la puerta PASS1, que debe generar un output positivo en cualquier caso —ya sea en presencia o ausencia de iones o de primers con mismatch— usaron una ADN polimerasa capaz de replicar el ADN con o sin malos apareamientos.
De esta manera se han podido desarrollar cuatro operaciones lógicas usando la maquinaria de replicación del ADN. Si queremos aplicarlo ahora mismo, sólo serviría para detectar la presencia o ausencia de estos metales en una determinada muestra. Por ejemplo, en un relave minero o en una muestra de suelo para la prospección minera.
Sin embargo, el trabajo de Park et al. da un punto de inicio para el desarrollo de nuevas puertas lógicas moleculares que permitan detectar señales mucho más complejas como la presencia de partículas virales en una determinada muestra, o la presencia de determinadas moléculas para agilizar el diagnóstico de ciertas enfermedades como la diabetes, o también para detectar sustancias prohibidas en la orina de los deportistas y ver si están haciendo trampa.
Y tal como en las puertas lógicas basadas en transistores, se podrían generar circuitos de puertas lógicas basadas en el ADN, con la ventaja que su tamaño es mucho menor y la rapidez de las reacciones permitirían acelerar la velocidad de procesamiento de las computadoras para poder realizar muchas más operaciones en un menor tiempo y con un menor gasto de energía. De esta manera, se podría comparar las secuencias genómicas de miles de especies, con millones de millones de secuencias nucleotídicas en unos pocos segundos.
Referencias:
Park, K. S., Jung, C. and Park, H. G. (2010), Inside Cover: “Illusionary” Polymerase Activity Triggered by Metal Ions: Use for Molecular Logic-Gate Operations (Angew. Chem. Int. Ed. 50/2010). Angewandte Chemie International Edition, 49: 9540. doi: 10.1002/anie.201006534
Tomas Carell. Molecular computing: DNA as a loguic operator. Nature 469, 45–46 (06 January 2011)
0 comentarios:
Publicar un comentario
Se respetuoso con tus comentarios y críticas. Cualquier comentario ofensivo será eliminado.